K-Means Clustering for Magic: the Gathering Decks - Card Recommendation
I apply K-Means Clustering to a Magic: The Gathering deck dataset and find whether it predicts the meta. Included is an explanation of how k-means works. This is a post from my old blog, so some parts may not represent my current opinions.
Unsupervised Learning has been called the closest thing we have to “actual” Artificial Intelligence, in the sense of General AI, with K-Means Clustering one of its simplest, but most powerful applications.
I am not here to discuss whether those claims are true or not. I will however state, that I am often amazed by how well unsupervised learning techniques, even the most rudimentary, capture patterns in the data that I would expect only people to find.
Today we’ll apply unsupervised learning on a Dataset I gathered myself. It’s a database of professional Magic: The Gathering decks that I crawled from mtgtop8.com, an awesome website if you’re into Magic: the Gathering.
I scraped the MtgTop8 data from a few years of tournaments, and they’re all available to be consumed in this GitHub repository.
If you’re not into the game, or even if you’ve never even played it, don’t worry: it won’t get in the way too much, as I will just explain the theoretical side of K-means Clustering and show you how to apply it using Dask, the parallel computing Python framework. If you are into the game, then you’re gonna love the examples.
K-Means Clustering
The algorithm we will look into today is called ‘K-means clustering’. It provides a way to characterize and categorize data if we don’t really know how to separate it before hand.
Why do we need Unsupervised Learning?
What do I mean by Unsupervised Learning? Suppose you had a set of pictures of cats and dogs. You could train a supervised Machine Learning model to classify the pictures into either category.
However, imagine you have a big, complex dataset of things you don’t know a lot about. For instance, you could have data about the light spectrum produced by different planets, and be looking for a way to group them into categories.
For another example, you could have loads of genetic data from many different organisms, and wish to define which ones belong to the same genus or families in an intuitive way.
Or, in our case, we could have 777 different Magic: The Gathering decks, using over 600 different cards (yeah, the professional meta is not that diverse), and want to train a machine learning model so that it understands which cards work well together and which ones don’t.
Now imagine you had to do this task, and you had no idea how to play this game. Wouldn’t it be nice if someone had invented an algorithm to cluster data together if they look similar, without you having to provide a definition for ‘similar’? That’s what clustering, and k-means clustering in particular, are all about.
Now that’s done, I hope you’re motivated, because it’s time to get our hands dirty with some theory.
How does K-Means Clustering work?
K-Means Clustering receives a single hyperparameter: k, which specifies how many clusters we want to categorize our data into.
The clusters won’t necessarily all have the same quantity of instances. However, they should each characterize a specific subset of our data. How will we achieve this? Let’s find out.
First, the input for this algorithm needs to be a set of vectors. That is, all your features should be numerical, and in the same order. If you had any categorical features, my advice would be to use one-hot encode: convert each categorical variable into a vector of n-elements: one for each possible category, all set to 0 except the one for the given category.
What the algorithm will do is initiate k random ‘centroids’ -points in the space defined by the dimensions of the dataset’s elements-, and then it will:
- Assign each element to the centroid closest to it.
- Remap the centroid to the point lying on the average of all the elements assigned to it.
- Repeat steps 1 and 2, until convergence (or a stopping condition, such as doing N iterations for a given N) is met. Convergence is usually defined as no instances changing their cluster label from one iteration to the next.
In the end, each element will have been assigned to one of k clusters, such that the elements in the same cluster all lie closest to it.
Here is a gif showing the algorithm in action, courtesy of Wikimedia Commons.
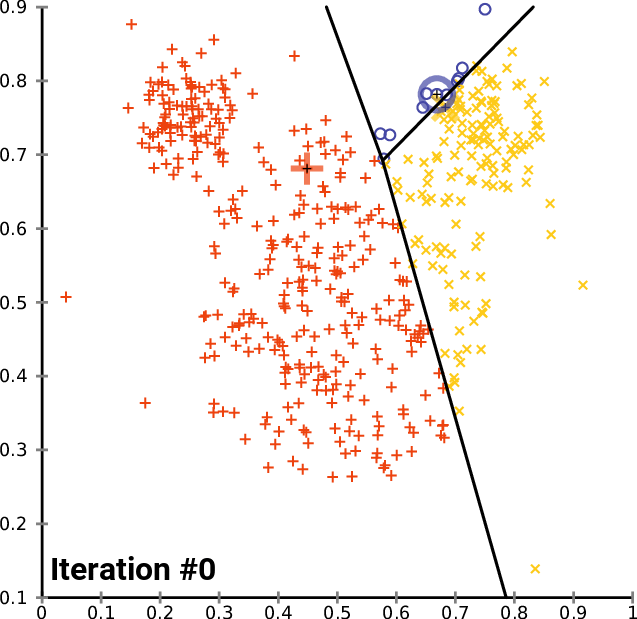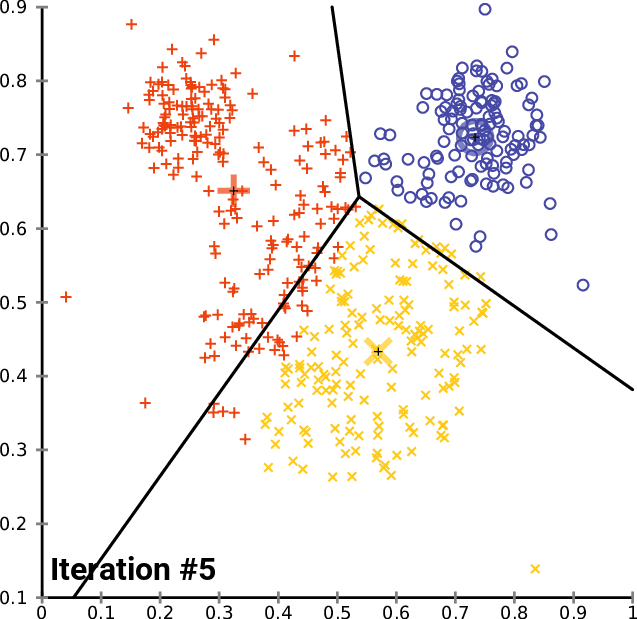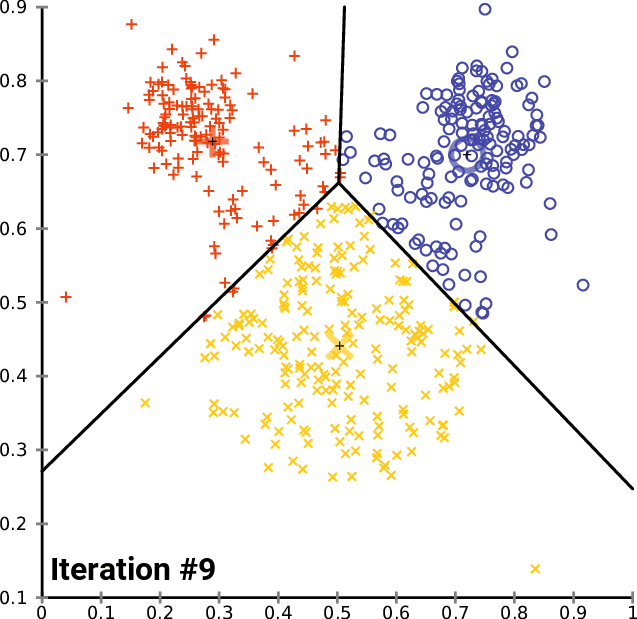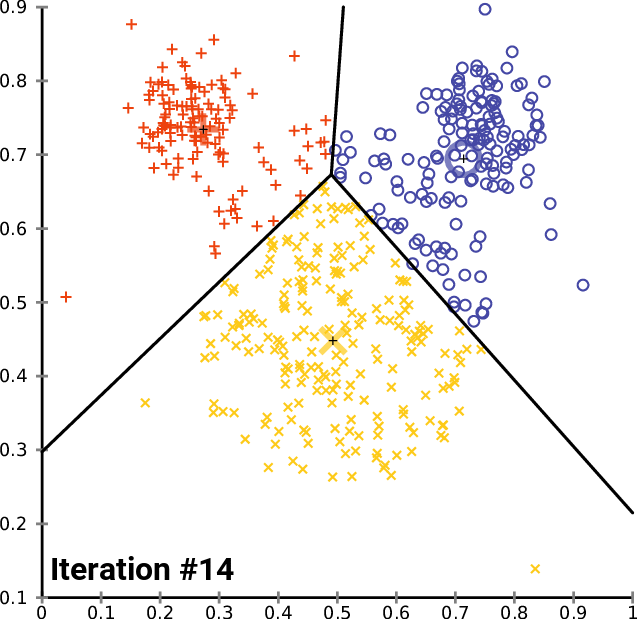
The crosses represent the position of each cluster’s centroid, and you can see how they start moving until they become stable. Notice also how they move more initially, and less over time.
Applications for K-means clustering
Like many other unsupervised learning algorithms, K-means clustering can work wonders if used as a way to generate inputs for a supervised Machine Learning algorithm (for instance, a classifier).
The inputs could be a one-hot encode of which cluster a given instance falls into, or the k distances to each cluster’s centroid.
For this project however, what we’ll be developing will be a (somewhat rudimentary) recommender system which will, given an instance, return elements appearing on the same cluster.
Using Dask’s K-means Clustering in Python
Having defined the concepts for this project, let’s now begin the practical part. The code is available in the Jupyter Notebook on this repository.
Processing the Data
I stored the decks following this format:
N card name
M another card name
in 777 different .txt files, where each line refers to a card, and the digits before the first space are the number of apparitions for that card in the deck.
In order to transform them into a more manageable format -I’ll be using a list of tuples (Int, String) for each deck, each tuple a card-, this is what we’ll do:
This is what a deck looks like now.
[(4, 'Ancient Ziggurat'), (4, 'Cavern of Souls'), (4, 'Horizon Canopy'),
(1, 'Plains'), (2, 'Seachrome Coast'), (4, 'Unclaimed Territory'),
(4, 'Champion of the Parish'), (1, 'Dark Confidant') ...]
Where each tuple represents a card (yes, those are real card names), and how many times it appears.
Since we want to map each deck to a vector, it seems intuitive to just
- Turn them into a list, with one element for each different card in the whole MtgTop8 dataset.
- Set each component to the number of apparitions for the corresponding card (with all the components corresponding to cards that do not appear in the deck set to 0).
To do that, let’s get all the different cards that appear in all the decks.
And now let’s use our newfound knowledge about card names to turn all decks into beautiful, consumable vectors.
Now all our decks can be easily fed into Dask’s K-Means Clustering algorithm, and we can play with the output.
We could have just used ‘binary’ vectors, and set the components to 1 if the card appears in the deck, and 0 if it doesn’t. We could also try that later and see if we get good results too.
Applying K-means Clustering
Now that our data is all neatly mapped to the vector space, actually using Dask’s K-means Clustering is pretty simple.
Where the most important part is the n_clusters argument, which I kind of arbitrarily set to 8.
In real life, you may want to experiment with different values. For this particular case, I know MtG has 5 different ‘colors’ for cards. To prevent the algorithm from just clustering the cards for their colors (which it didn’t do at all anyway), I chose a number bigger than 5.
The algorithm returns the labels as a Dask Array. I may do an article on how to use those later, but right now I didn’t want to deal with all that. Also, the MtgTop8 dataset is small enough for that to not matter that much, so I decided to convert it back to a list of integers. Sue me.
Exploratory Analysis: Let’s see what we got
At first I wanted to check if the results made any sense. This was my first time using K-means Clustering on this dataset, and I wanted to make sure it had learned something valuable. So I just checked which cards were most frequent in the decks from each cluster. The results were, at least to me, astounding. Here’s what I did to check.
If you’re interested in the results, here’s a separate article about them. I just didn’t want to mix my M:tG findings with this tutorial so that readers who are into Data Science but not into the game won’t be bored. In case you’re interested, I later wrote about a completely different application for K-Means Clustering: image filters.
I also strongly encourage you to download the notebook from the GitHub project and play with it, it’s honest fun.
Card Recommendations using K-Means Clustering
Now we made that sanity check, we can proceed with the actual application for all the labels we generated.
There are many ways we could have approached the recommendation problem: given a card, suggest other cards that go well with it, without using any data about the cards except which decks they appear in (that is, no cheating and asking for more data about the cards like color, price, or an expert’s opinion).
Think for a moment, how would you use the clusters data to generate the recommendations? I’m sure you could come up with a few ideas.
If what you came up with is not what I’m about to do, please tell me. Creativity is more fun if it’s a team effort, and I really want to see what my dear readers come up with.
Finally, here’s what I did:
As you can see, I omit how many times a card appears on a given deck for this part, and just look at the relative number of apparitions for a card on a given cluster.
I then return the cards with the most similar relative apparitions (defined by Euclidian distance).
If you’re a Magic: The Gathering player, try out this code and see the results. It makes reasonably good (though kind of conservative) recommendations.
Conclusion
K-Means clustering allowed us to approach a domain without really knowing a whole lot about it, and draw conclusions and even design a useful application around it.
It let us do that by learning the underlying patterns in the data for us, only asking that we gave it the data in the correct format.
I encourage you to play with the code here, and try making your own recommendation’s system with a different Dataset, or solving some other problem. If you do, please show me your results. I wanna see what you come up with.
In the future, I’d like to do this same analysis using non-professional decks. That way, I could make a recommendations engine for casual players (like me). I think it would be cool if it worked with almost any card, and not just 642.
If you want to delve deeper into Unsupervised Learning, I can’t recommend Introduction to Statistical Learning enough. That’s the book I learned about K-Means Clustering from. It’s also the book thanks to which I finally understood Boosted Trees, though that’s a tale for another article.
Liked this article? Then please follow me on Twitter. Let me know if you found the article helpful, or if any of it sounds wrong or doesn’t work.
Happy coding.