TransGAN
Notes on the paper proposing TransGAN, a GAN architecture without convolutions, purely based on transformers.
https://arxiv.org/pdf/2102.07074.pdf
“We have proposed TransGAN, a new GAN (Generative Adversarial Networks) paradigm based on pure transformers. We have carefully crafted the architectures and thoughtfully designed training techniques. As a result, TransGAN has achieved comparable performance to some state-of-the-art CNN-based GAN methods across multiple popular datasets. We show that the traditional reliance on CNN backbones and many specialized modules may not be necessary for GANs, and pure transformers can be sufficiently capable for image generation.”
They reach state-of-the-art results on STL-10 which is a bigger image classification dataset, but not on CIFAR10. They come to the conclusion that TransGANs are very data-hungry.
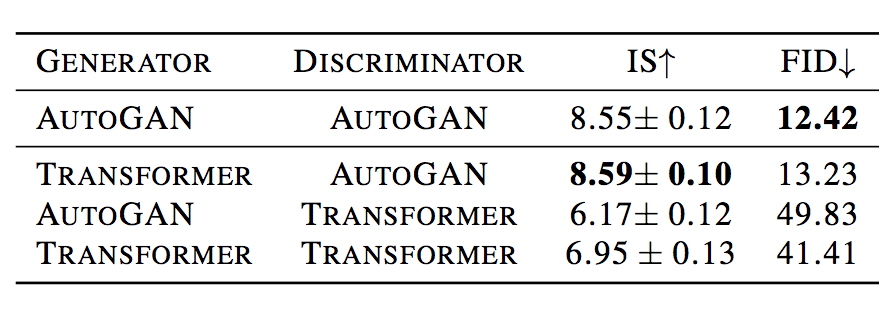
They try mixing a CNN based discriminator with transformer based generators and vice versa, and these are the results:
TransGAN Architecture
This is what the generator and discriminator architectures look like for TransGAN.

“The discriminator takes the patches of an image as inputs. We split the input images into 8 × 8 patches where each patch can be regarded as a “word”. The 8 × 8 patches are then converted to the 1D sequence of token embeddings through a linear flatten layer, with token number N = 8 × 8 = 64 and embedding dimension equal to C.
After that, the learnable positional encoding is added and a [cls] token is appended at the beginning of the 1D sequence. After passing through the transformer encoders, only [cls] token is taken by the classification head to output the real/fake prediction.”
Related Reading
- My notes on Deep Learning with NLP: Transformers
- On the “Transformers for Everything” theme: Do Transformers See Like Convolutional Neural Networks?.
- See also my notes on GANs, where I summarize Goodfellow’s survey of the field.