Stable Diffusion: Prompt Guide and Examples
I wrote this post when Stability AI had just released the AI art model Stable Diffusion. In this guide, you will learn how to write prompts by example. If you want, you can skip the discussion and examples and just go straight to the prompt template and explanation
Stable Diffusion is similarly powerful to DALL-E 2, but open source, and open to the public through Dream Studio, where anyone gets 50 free uses just by signing up with an email address.
Since it is open source and anyone who has 5GB of GPU VRAM can download it (and Emad Mostaque, Stability.ai’s founder has come out and said more efficient models are coming) to get unlimited uses, expect to keep seeing headlines about AI art for a while.
I am tired of repeating the same old speech, but thinking back to how primitive models were just a year and a half ago with DALL-E and other VQVAE, this is completely insane. I can only imagine what applications artists and other users will come up with in the near future by leveraging StableDiffusion’s embeddings and its text-to-image capabilities, let alone whatever the next generation of models will be able to do.
Extrapolating from how much this field has grown in the last 18 months, I wouldn’t be surprised if in 2 more years you can write a script for a comic book, feed it to some large language encoder and a text-to-image model like this, and get a fully illustrated, style-coherent graphic novel. This would also apply for frames for an animated movie or a storyboard.
Are we really that close to something so big? I feel like the technology is there if enough compute and budget were allocated, but I am not sure whether someone will do it. I don’t see any obvious blockers or barriers to the next generation of models being even bigger or understanding style better.
Given this context, many people are concerned some artists may lose their jobs. After lots of discussion in Reddit and at parties, I will try to summarize my current opinion on that topic.
For use-cases where having a human artist brings the least value, I think text-to-image models will dominate the market. However, for those cases I think we already had stock images. For instance if I am adorning a random blog post, I’d rather get a free stock image in the header than pay an artist for a new professional photo, as I don’t think my readers care that much (see “I replaced all our blog thumbnails using DALL·E 2” for an example).
Especially if this site was monetized and the big picture was just there to make you scroll further down and get more engagement and ad views.

For cases where the artist’s vision matters, like original paintings for decorating my home, or the panels for a graphic novel, I think StableDiffusion or DALL-E 2 for that matter are far away from beating humans. So far.
However, I guess many freelance artists who work for commissions may find less demand for their work as bloggers or random people get their art itch scratched by AI art. I would love to hear the opinion of artists from that sort of market on this, as I am quite ignorant of how the whole process works (for instance, what kind of people commission art in the first place).
I think models like this can also enhance artists’ work. Say you are asked to draw 5 illustrations of a character doing different things. You could use dall-e to get 5 relevant background scenes in 5 minutes, then use your time to add in the characters and some details on top of them. AI art models are significantly better at drawing background scenes than action and characters, so this is a combination of the best capabilities of both human and machine.
Compare against drawing the whole thing from scratch.
Obviously style matching would not be easy, but when we reach a point where you can supply your own mini dataset of backgrounds to condition on and style transfer, this may make artists able to work much faster.
Now is this a good thing? I guess it is a double edged sword: will artists who leverage AI art models to become more productive drive down the general price of art? Or will the new supply generate new demand? I am not an economist, nor an artist, so speculating further would be futile and I will leave the rest to my dear readers.
Speculate away, please.
Extra reflection on the topic: As I said on Reddit, I would be worried that eventually you may remove the artist from some parts of the design loop if user feedback or artist feedback could be used as a reward for a reinforcement learning agent.
Something like asking “did you like this city’s design / this building? 1 to 10” to users, and using this for a policy gradient or similar algorithm.
I am reminded of Evolution through Large Models where this approach is used for autogenerated instances made through genetic mutation algorithms. Imagine the same but for text-to-image.
Stable Diffusion Art
As in my DALL-E 2 article, I tried the same prompts I had already tried in Craiyon or Guided diffusion (I know, that’s so early 2022!) to show just how much these systems have improved.
My focus was on fantasy, science fiction, and steampunk illustrations, because that is what I like, but I also experimented with more complex scenes and descriptions, to see how well StableDiffusion understands things like scene composition, prepositions and element interactions.
As with DALL-E 2, I found the model yields much better results for prompts that do not ask for a certain action or verb to be performed, but rather static scenes, especially if there are no humanoids or moving characters in them.
For everything else though, the results were astounding. I feel like StableDiffusion beats DALL-E 2 in character design and realism, but loses in the beauty of its landscapes and backgrounds, but take this with a 10% certainty as it is only my intuition and is likely be biased by my prompt choices.
One thing I’ve found helps a lot in getting more beautiful results is thinking of which exact visual effect would add to the picture, and specifying it. For instance, for fantasy illustrations usually adding fireflies or sparkles helps. For landscapes, I like naming specific flowers like azaleas, and for buildings naming features like a column, a fountain, or anything else to ground the picture in a certain time and place, even if the detail is only tangential to the whole picture.
In my opinion these details can steer the model even better than many vague cues like “4k”, in this generation of models -unlike in CLIP or GLIDE-. See Appendix A: StableDiffusion Prompt Guide to see how I choose most of my prompts, and some advice.
Prompt Examples and Experiments
I will begin with some scenes that I already tried with other models. These are some of the stable diffusion prompts that I liked best.
“A digital illustration of a steampunk library with clockwork machines, 4k, detailed, trending in artstation, fantasy vivid colors”



I like the last one especially.
“A digital illustration of a steampunk flying machine in the sky with cogs and mechanisms, 4k, detailed, trending in artstation, fantasy vivid colors”





For scene composition, it is still struggling. Here are a ferret and a badger (which the model turned into another ferret) fencing with swords.

As expected, some of the best prompts that had worked for DALL-E 2 and Craiyon worked great with stable diffusion too.
A digital Illustration of the Babel tower, 4k, detailed, trending in artstation, fantasy vivid colors



Cluttered house in the woods, anime, oil painting, high resolution, cottagecore, ghibli inspired, 4k




In my opinion, both prompts yielded better images here than they did for DALLE-2, but you can be the judge of that.
A digital illustration of a medieval town, 4k, detailed, trending in artstation, fantasy



A medieval town with disco lights and a fountain, by Josef Thoma, matte painting trending on artstation HQ, concept art
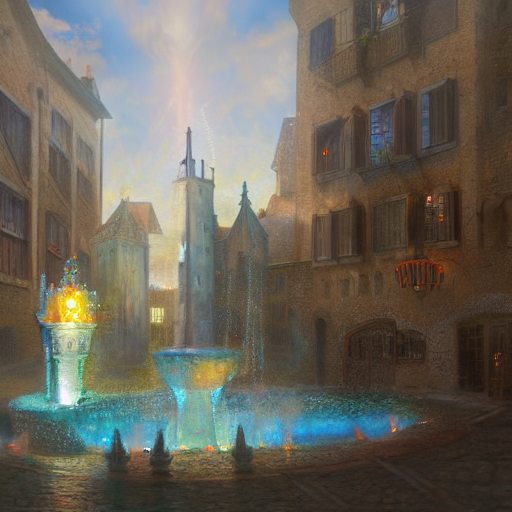


A digital illustration of a treetop house with fireflies, vivid colors, 4k, fantasy [,/organic]





Lest you think these models can only do 2d art, here is a very good photograph prompt for Stable Diffusion.
Editorial Style Photo, Bonsai Apple Tree, Task Lighting, Inspiring and Awesome, Sunset, Afternoon, Beautiful, Symmetric, 4k

The general format is:
Editorial Style Photo, (Low Angle|Eye Level), ${THING YOU WANT}, Task Lighting, {MATERIALS}, {STYLE ADJECTIVES}, Symmetric, 4k
I’ve found this prompt works wonderfully well with DALLE, but it does not produce images with the same quality for Stable Diffusion. Here’s the same prompt’s output in DALLE.


This prompt format originally due to Nick St. Pierre (@nickfloats).
Paintings of Landscapes
Again back to comparing with DALL-E 2 and Craiyon, I tried asking for landscape paintings of mansions, castles and general garden scenes. I expected a more classical feel as opposed to the more digital illustration like air of the images from before.
A beautiful castle beside a waterfall in the woods, by Josef Thoma, matte painting, trending on artstation HQ



A beautiful mansion with flowered gardens and a fountain, digital illustration, 4k, detailed, bokeh



A beautiful mansion beside a waterfall in the woods, by josef thoma, matte painting, trending on artstation HQ


A beautiful mansion with flowered gardens and a fountain, painting, oil on canvas, 4k, detailed, thomas cole



A beautiful mansion with flowered gardens and a fountain, painting, oil on canvas, 4k, detailed, bokeh




Style cue: Steampunk / Clockpunk
A digital illustration of a steampunk robot [/with cogs and clockwork by Josef Thoma], 4k, detailed, trending in artstation, fantasy vivid colors






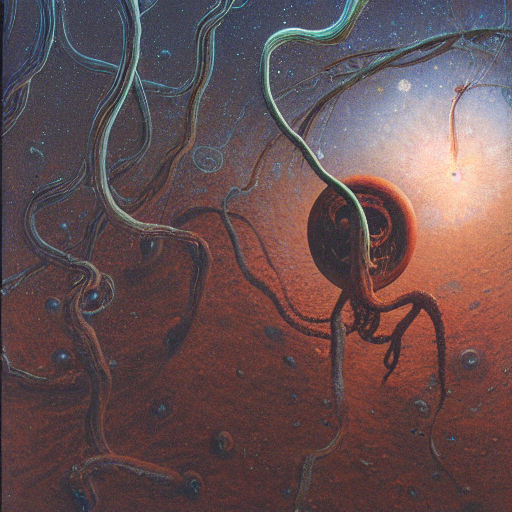
Recommended Style Cue: Beksinski
I tried adding the name of the painter Beksinski as a style cue, and the results were mixed: many of them blocked by StableDiffusion’s content policy, which I guess means there was something awful in them, but the survivors looked amazing.





Anthropomorphic Animals (Mostly dressed as adventurers)
One thing I struggled to get right with other models was anthropomorphic animals, especially if I also asked for medieval, steampunk or fantasy clothes. My dream of drawing a Mouseguard party with DALL-E would never come to fruition. With StableDiffusion one trick that worked for me was, instead of, say, prompting “ferret with pirate clothes/dressed as a pirate”, using the prompt “ferret wearing a pirate costume”.
Then I also got a prompt from Twitter and iterated it, which was “cute and adorable [animal], wearing [clothes], steampunk/clockpunk/fantasy…” plus style prompts.
This one worked like a charm. Rather than telling you the prompt I used for each individual picture, I will just show you the ones I liked best, so you can see what possibilities exist by tweaking a prompt like that one (I guess you can deduce the animal, etc. from the images themselves).
Example prompt: “Cute and adorable ferret wizard, wearing coat and suit, steampunk, lantern, anthromorphic, Jean paptiste monge, oil painting”
In general, removing Jean Paptiste Monge didn’t change results that much, switching coat and suit by tailcoat gave me the results I liked best, and adding portrait made all the paintings into humans. Also, the lantern keyword was copied from Twitter but it didn’t really bring much to the table (And most of these animals aren’t carrying a lantern because of that).




















I really went crazy with these, and these are my selection, so you can imagine how many I tried.
Forest Scenes
Another thing that I love about StableDiffusion (Which DALL-E 2 also gets right) is how well it renders textures. I can imagine how a 3d artist may use one of these models to enhance their own 3d objects by creating many different textures fast and combining them with domain knowledge.
Because of that, and my love for moss, I made many forest scenes with abundant growth and moss. Many of these look like a Magic: the Gathering illustration. I will not post the prompts as each one was different, but they mostly followed my digital fantasy illustration template.







StableDiffusion was the first AI art model where I have successfully got a centaur. Not a deformed monstrosity, not a horse, not a weird human. A real centaur! So that made me happy and I had to share it.
I honestly made a lot more illustrations I loved (like 400 total, I think?) but I guess most readers will get bored long before they finish scrolling this post, so I will not keep you any longer.
These are the last ones, I swear.


Before we reach the end, I want to raise a concern and propose a challenge. No matter what I tried, I could not make either DALL-E 2, or StableDiffusion make characters in the style of Jojo’s Bizarre Adventure (or Araki, in general). I tried the obvious style cues and others, and none worked. So if any of you manages to make one of these models draw Spongebob Squarepants in the style of Jojo’s, or any other recognizable character, you will get a thousand internet points from me.
Appendix A: Stable Diffusion Prompt Guide
In general, the best stable diffusion prompts will have this form:
“A [type of picture] of a [main subject], [style cues]*”
Some types of picture include digital illustration, oil painting (usually good results), matte painting, 3d render, medieval map.
The main subject can be anything you’re thinking of, but StableDiffusion still struggles with compositionality, so it shouldn’t be more than one or two main things (say, a beaver wearing a suit, or a cat samurai with a pet pug). The main subject should be mostly composed of adjectives and nouns. Avoid verbs, as Stable Diffusion has a hard time interpreting them correctly.
Style cues can be anything you want to condition the image on. I wouldn’t add too many, maybe only 1 to 3. These can really vary a lot but some good ones are: concept art, steampunk, trending in artstation, good composition, hyper realistic, oil on canvas, vivid colors.
Additionally, adding the name of an artist as a cue will make the picture look like something that artist made, though it may condition the image’s contents, especially if that artist had narrow themes (Beatrix Potter gets you spurious rabbits, for instance).
For a detailed guide to crafting the best stable diffusion prompts, see A Guide to Writing Prompts for Text-to-image AI if you feel like you want to read more.
You can also find many great prompts if you use the Lexica.art prompt search engine to find images you like and make tweaks to their prompts.
Appendix B: Resources and Links
Given how much has happened lately (even John Oliver is talking about DALL-E!), here are some other articles you may want to read.
- Stable Diffusion: The Most Important AI Art Model Ever covering the more social/economic side of this.
- A traveler’s guide to the latent space: a guide on prompt engineering that goes really in depth. I haven’t actually read the whole thing.
- A guide to Writing Prompts for Text-to-Image AI: The best quick primer I’ve found on prompt engineering and writing prompts for DALL-E 2/StableDiffusion or any other text-to-image AI.
- Art Prompts: My Experiments with Mini DALL-E: My first post on text-to-image AI, where I included my own AI art prompt guide. Here you can see how far we’ve come and how fast.
- DALL-E 2 Experiments: The post I wrote two weeks ago when DALL-E 2 beta release was news and StableDiffusion hadn’t come out yet. See if you can spot the same prompts’ different results.
- How to Draw: Where a user uses StableDiffusion’s img2img version to convert an MSPaint drawing into a realistic sci-fi image.
- Image2Image StableDiffusion, available on Replicate for free. You can draw a rough sketch of what you want in jspaint (the browser copy of MSPaint), then upload it to Stable Diffusion img2img and use that as a starting point for your AI art. See also Stable Diffusion is a really big deal, Simon Willison: This came out a little after I wrote this post, when Stability.ai released the img2img StableDiffusion model. It is amazing! You can make a sketch in MSPaint (Or JsPaint) and make the AI turn it into a painting or illustration in the style you want.
- High-performance image generation using Stable Diffusion in KerasCV: Stable Diffusion was finally ported to keras. It runs smoothly both on GPU or CPU if you have keras installed, and this is the version I’ve been using to make AI art in my local computer.
- Lexica.art a great search engine for prompts and artworks. It is an amazing resource to find good images and see which prompts generated them, which you can then copy and tune to your needs. An easy way to build on the best stable diffusion prompts other people has already found.
- If you like anime, Waifu Diffusion is a text-to-image diffusion model that was conditioned on high-quality anime images through fine-tuning, using Stable Diffusion as a starting point. It generates anime illustrations and it’s awesome.
- The Illustrated Stable Diffusion explains how Stable Diffusion works, step by step and through different levels of abstraction, and has great illustrations.
If you liked this article, please share it with someone you think will like reading it too. I wrote this for you guys.